Entwicklungszyklus
Reiternavigation
Beschreibung
Die Komponentenentwicklung findet in iterativen Zyklen statt, die den Reifegrad des Gesamtsystems kontinuierlich steigern. Die Zyklen bestehen aus einem Verfeinerungsschritt, einer Phase der parallelisierten Komponentenentwicklung und einem Checkpoint inklusive der Bewertung der Fortschritte. Die Ergebnisse der Bewertung führen abschließend zu der Entscheidung, ob das Gesamtsystem gemäß den Anforderungen fertig gestellt ist.
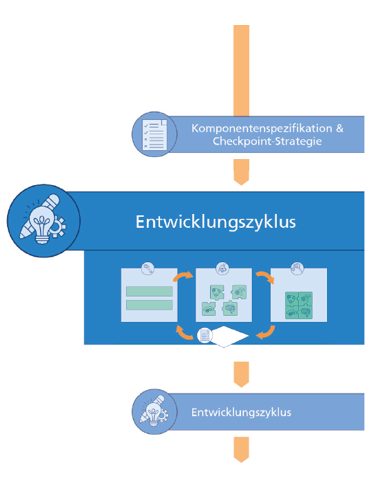
Die Verfeinerung findet auf Basis der Ergebnisse von Checkpoint/Bewertung statt. Der Lösungsansatz, der zur Realisierung der jeweiligen Komponentenspezifikation gewählt wurde, wird detaillierter ausgearbeitet oder falls nötig, variiert. Eine Variation der komponentenspezifischen Lösungsansätze ist in den ersten Zyklen des Entwicklungszyklus sinnvoll, um keine Lösungen von vornherein auszuschließen. In späteren Zyklen sollte nur noch an der detaillierten Ausgestaltung der Lösungsansätze gearbeitet werden, um den Reifegrad des Produkts kontinuierlich zu erhöhen. Der Schritt der Verfeinerung findet interdisziplinär statt, um die Abhängigkeiten zwischen den Komponenten zu berücksichtigen. Anschließend werden entsprechende Anpassungen bezüglich des Systemmodells sowie der Komponentenspezifikation vorgenommen. Hierbei kann es insbesondere zu einer weiteren Dekomposition von Komponenten kommen, etwa um Engpässe bei der Entwicklung zu vermeiden, oder es können zusätzliche Komponenten hinzugefügt werden, wenn z. B. neue Datenquellen und Datensätze einbezogen werden.
Grundlegend für die parallelisierte Komponentenentwicklung sind die Komponentenspezifikationen, die zu erfüllen und zu validieren sind. Die Entwicklung findet für jede Komponente nach einem individuell geeigneten und domänenspezifischen Vorgehen statt. Bei klassischen Komponenten wie mechanischen oder elektrischen Subsystemen kann beispielsweise auf ein Vorgehen aus dem Systems Engineering zurückgegriffen werden. Voraussetzung ist, dass sich dieses Vorgehen in das hier beschriebene zyklische Prinzip integrieren lassen. Für die ML-Komponentenentwicklung sowie die Datenbereitstellung gibt PAISE® das Vorgehen vor.
Wurde ein Lösungsansatz für eine Komponente umgesetzt (egal ob prototypisch oder verfeinert), so kann sie in das umgebende Gesamtsystem oder das umgebende Subsystem integriert und innerhalb von Integrationstests validiert und verifiziert werden. Checkpoints synchronisieren diese Integration von Subsystemen. Komponenten können auch passiv an Checkpoints teilnehmen, wenn z.B. der Entwicklungsstand keine Integration zulässt. Bei der Integration wird dann bezüglich dieser Komponente auf den Entwicklungsstand des vorherigen Zyklus aufgesetzt, auf Simulationen zurückgegriffen oder es werden nur die Schnittstellen getestet. Abschließend findet eine Bewertung statt, mit entsprechender Dokumentation des Entwicklungsstands aller Komponenten und der Ergebnisse bezüglich des Gesamtsystems. Die Dokumentation sollte insbesondere bei ML-Komponenten durch einen Versionierungsprozess unterstützt werden, der die verwendeten Daten mit einschließt.
Insgesamt dient der Checkpoint dazu interdisziplinäre Querschnittsaspekte in den Blick zu nehmen. Neben der Betrachtung von funktionaler Sicherheit oder auch der Kosten beinhaltet das ggf. auch die offene Diskussion potentieller ethischer Konflikte, die etwa durch die Nutzung von unvollständigen Daten oder Daten mit enthaltenen Verzerrungen (Bias), erzeugt werden können. Solche Aspekte werden gezielt von der Rolle des oder der Datenbeauftragten adressiert und sind ebenso im Vorgehen der Datenbereitstellung verankert.
Das beschriebene „checkpoint-basierte“-zyklische Vorgehen hat eine stetige Verbesserung des Gesamtsystems zum Ziel. Dabei birgt es drei Eigenschaften, die aus unserer Sicht für KI-Engineering essenziell sind:
- Es berücksichtigt, dass die (Weiter-)Entwicklung mancher Komponenten von den Ergebnissen anderer abhängig ist. Beispielsweise kann die Entwicklung einer ML-Komponente erst dann effektiv stattfinden, wenn erste Daten vorhanden sind. Genauso kann die Konzeption eines Subsystems, das durch ML-basierte Methoden optimiert werden soll, erst nach der Entwicklung des zugehörigen ML-basierten Hilfssystems begonnen werden. Die Abhängigkeiten der Komponenten untereinander gehen aus dem Systemmodell hervor. Nützlich kann hier zusätzlich eine zeitliche Abhängigkeitsdarstellung ähnlich der eines Gantt-Charts sein, wobei darauf zu achten ist, dass bei einem agilen Vorgehen nicht mit absoluten Zeitintervallen geplant werden kann.
- Es ermöglicht ein exploratives Vorgehen, das speziell für die Entwicklung von ML-basierten Komponenten notwendig ist, da hier im Voraus oft keine Garantien gegeben werden können, ob alle Anforderungen erfüllt wurden.
- Es bietet den Rahmen für eine risikobasierte Entwicklung, die alternative Lösungsansätze zulässt, diese auf Basis von Prototypen gegeneinander abwägt und bezüglich ihrer Risiken bewertet. So muss nicht zwingend davon ausgegangen werden, dass eine Komponente als ML-Komponente entwickelt wird. Beispielsweise kann sich herausstellen, dass ML-basierte Methoden nicht geeignet sind und auf klassische statistische Verfahren zurückgegriffen werden sollte.
- Gerade während der ersten Entwicklungszyklen kann es sich auszahlen, verschiedene Alternativen auch unter einem größeren Risiko grob zu betrachten während das Risiko in späteren Phasen immer weiter reduziert wird. Die Risikoanalyse ist damit essenzieller Teil dieser Phase
Nicht alle Zyklen müssen dieselbe Länge besitzen, vielmehr können sie sich an organisatorische Gegebenheiten anpassen.
Das zyklische Modell - die Bestandteile
→ Zur nächsten Phase von PAISE® : Übergabe
← Zurück zur vorherigen Phase von PAISE®: Komponentenspezifikation und Checkpoint-Strategie
Tablesort – Anwendungsfall Produktion
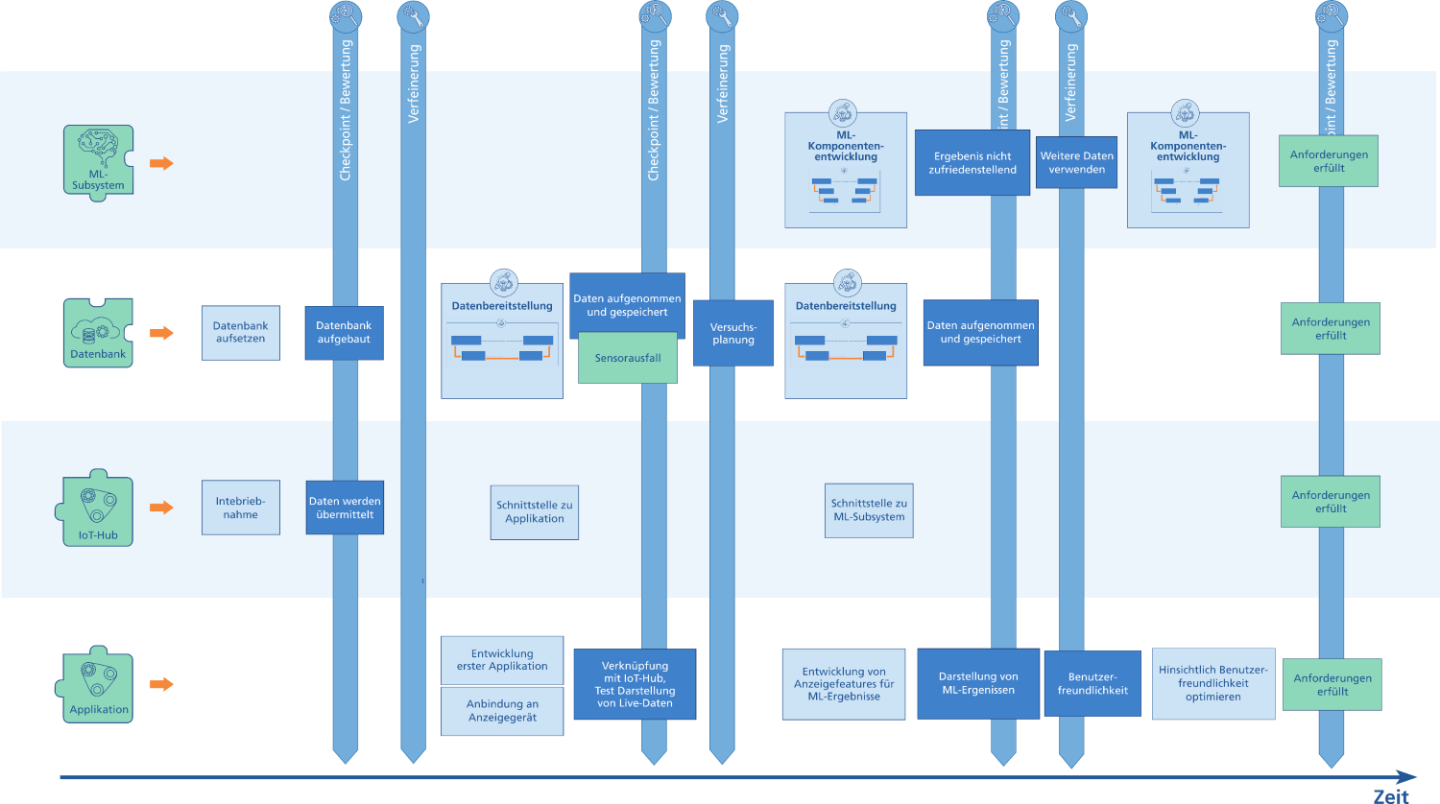
In dieser Phase erfolgen die Entwicklung, Testung und Inbetriebnahme der einzelnen Komponenten aus der funktionalen Dekomposition. Die Phase läuft in mehreren Zyklen ab, in denen verschiedene Lösungsansätze für die Komponenten probiert und deren Reifegrad stückweise erhöht wird. Die Aktivitäten in den einzelnen Zyklen bestehend aus Entwicklung, Checkpoint und Verfeinerung sind für dieses Beispiel in untenstehendem Schaubild dargestellt.
Im ersten Zyklus erfolgt die Anbindung des OPC-UA Servers des Tablesorts an den IoT-Hub und eine Datenbank initialisiert wird Zum Checkpoint wird die Übermittlung der Daten vom TableSort über den IoT-Hub zur Datenbank getestet. Wurde dies verifiziert, können die weiteren Komponenten umgesetzt werden. Dazu wird im zweiten Zyklus der Prozess der Datenbereitstellung durchlaufen, in dem Trainings- und Testdatensätze in der Datenbank abgelegt werden. Parallel dazu wird mit der Entwicklung der Applikation begonnen. Hierbei wird auf klassische Methoden der Softwareentwicklung (z.B. Scrum) zurückgegriffen.
Beim Checkpoint wird festgestellt, dass während der Datennahme ein Sensor ausgefallen war. Die Daten werden nichtsdestotrotz im dritten Zyklus zur Entwicklung eines ersten ML-Subsystems verwendet. Gleichzeitig wird der Sensorausfall behoben und es werden neue Test- und Trainingsdaten aufgenommen. Parallel dazu läuft die Entwicklung der Applikation weiter hinsichtlich verschiedener Darstellungen der ML-Ergebnisse. Beim Checkpoint wird festgestellt, dass das ML-Subsystem erwartungsgemäß Anomalien in der Verteilung der Bohnen noch nicht zuverlässig genug erkennt. Es können jedoch die Ergebnisse des ML-Subsystems erfolgreich in durch die Applikation visualisiert werden. Es folgt ein fünfter Entwicklungszyklus, in dem das ML-Subsystem auf Basis der im vorherigen Zyklus gewonnen Daten weiterentwickelt wird und die Applikation hinsichtlich Nutzerfreundlichkeit optimiert wird. Beim folgenden Checkpoint wird festgestellt, dass das ML-Modell nun zuverlässig Anomalien in der Bohnenverteilung erkennt, alle Komponenten miteinander integriert werden können und wie gewünscht operieren. Es sind alle Anforderungen an das Gesamtsystem erfüllt sind. Somit folgt die Übergabe des Systems in Phase 6.
→ Zur nächsten Phase von PAISE® am Beispiel TableSort: Übergabe
← Zurück zur vorherigen Phase von PAISE® am Beispiel TableSort: Komponentenspezifikation und Checkpoint-Strategie
Notbremssystem – Anwendungsfall Mobilität
In dieser Phase findet die Entwicklung aller Sub- und Hilfssysteme statt. Für eine übersichtliche Darstellung in nebenstehender Abbildung beschränken wir uns hier nur auf die Subsysteme Kamera, Detektor und Entscheider sowie auf den Cityscapes-Datensatz, der für die Entwicklung des Detektors bereitgestellt wird. Die einzelnen Aktionen sind nur abstrakt dargestellt und werden hinsichtlich ML-Komponentenentwicklung und Datenbereitstellung in den folgenden Abschnitten genauer ausgeführt.
Zu Beginn wird der Cityscapes-Datensatz aufbereitet (siehe ausführliches Beispiel im folgenden Kapitel) und als Komponente mit einer definierten Schnittstelle gekapselt. Am ersten Checkpoint findet der Test der Schnittstellen zwischen Cityscapes-Datensatz und Detektor sowie zwischen Cityscapes-Datensatz und des Entscheiders statt. Dieser ist erfolgreich, sodass im Verfeinerungsschritt keine Anpassungen bei den Spezifikationen, der Dekomposition oder den Schnittstellen vorgenommen werden müssen. Weiterhin wird als Ziel für die folgende Komponentenentwicklung die Entwicklung einer ersten prototypischen Version des Detektors und des Entscheiders festgelegt. Zeitgleich wird der Auswahlprozess des Subsystems Kamera gestartet.
Am zweiten Checkpoint nehmen Kamera, Detektor und Entscheider teil. Detektor und Entscheider sind prototypisch basierend auf initial abgeschätzten Spezifikationen entwickelt worden. Die spezifizierten Kameraparameter werden mit den Annahmen des Detektors abgeglichen – es zeigt sich, dass die ausgewählten Parameter im Wesentlichen mit den Trainings- und Testdaten aus dem Cityscapes-Datensatz übereinstimmen. Jedoch erreicht der Detektor nicht die erforderliche Zuverlässigkeit der Detektion, die der Entscheider vorausgesetzt hat. In der Verfeinerung wird beschlossen, die Kameraspezifikation beizubehalten, jedoch sowohl für Detektor als auch für Entscheider neue Zielwerte vorzugeben: Der Detektor soll seine Leistung verbessern, der Entscheider soll seine Robustheit gegen Detektionsschwächen steigern und somit seine Anforderungen an die Detektorleistung senken. Zeitgleich wird der Beschaffungsprozess der Kamera gestartet, der sich über die nächsten zwei Zyklen erstreckt. Im Verlauf der folgenden Komponentenentwicklung erreicht der Entscheider die spezifizierten Zieleigenschaften auf den bisherigen Testdaten. Während der Integrationstests im Checkpoint ergibt sich jedoch, dass im Zusammenspiel von Detektor und Entscheider noch weniger als 99 Prozent der im Datensatz enthaltenen kritischen Situationen auch als solche bewertet werden. In der Verfeinerung wird entschieden, dass das größere Optimierungspotenzial beim Detektor liegt und der Entscheider vorerst auf seinem aktuellen Stand belassen wird. Die Komponentenentwicklung konzentriert sich nun auf die Weiterentwicklung des Detektors. Am nachfolgenden Checkpoint wird das Zusammenspiel zwischen Detektor und Entscheider wieder getestet. Zusätzlich kann die inzwischen gelieferte Kamera an den Detektor angebunden werden, damit erste funktionale Tests durchgeführt werden können. Nachfolgende Schritte umfassen das Erheben und Annotieren von Realdaten mit dem Ziel-Kamerasystem, um den Entwicklungsstand des Detektors innerhalb des Gesamtsystems zu bewerten.
→ Zur nächsten Phase von PAISE® am Beispiel Notbremssystem: Übergabe
← Zurück zur vorherigen Phase von PAISE® am Beispiel Notbremssystem: Komponentenspezifikation und Checkpoint-Strategie