Um die Leistungsfähigkeit von KI-Systemen zu gewährleisten, müssen der Umfang und die Qualität der Trainingsdaten entsprechend gestaltet sein. Der Umfang der Daten könnte durch Sammeln/Aufzeichnen von weiteren Daten erhöht werden, das ist jedoch zeit- und kostenaufwendig. Zusätzlich steigert es den Aufwand für das Daten-Labeling. Die Qualität der Daten kann durch Aussortierung von Aufnahme- oder Labeling-Fehlern sowie die Steigerung der Abdeckung der Trainingsdaten verbessert werden. DAfA ist eine Sammlung von datengetriebenen Methoden um dies zu gewährleisten.
Zur Detektion von Fehlern können verschiedene Daten verknüpft werden, um unerwünschte Korrelationen oder unplausible Messwerte aufzuzeigen. Zu diesem Zweck kann ein aufgezeichneter Datensatz durch nachträgliche Anreicherung mit zusätzlichen Daten aufgewertet werden. Durch die Verfügbarkeit von GPS oder Zeitstempeln können so externe Datenquellen verwendet werden, um die einzelnen Datenpunkte mit weiteren Informationen zu hinterlegen. Das können beispielsweise Verkehrsdaten, Wetterdaten oder Kartendaten sein. Wenn beispielsweise unzulässige Fahrmanöver in einem Datensatz gefiltert werden sollen, können die Daten im Nachhinein mit den an diesem Ort gültigen Geschwindigkeitslimits eines externen Kartendienstes angereichert werden.
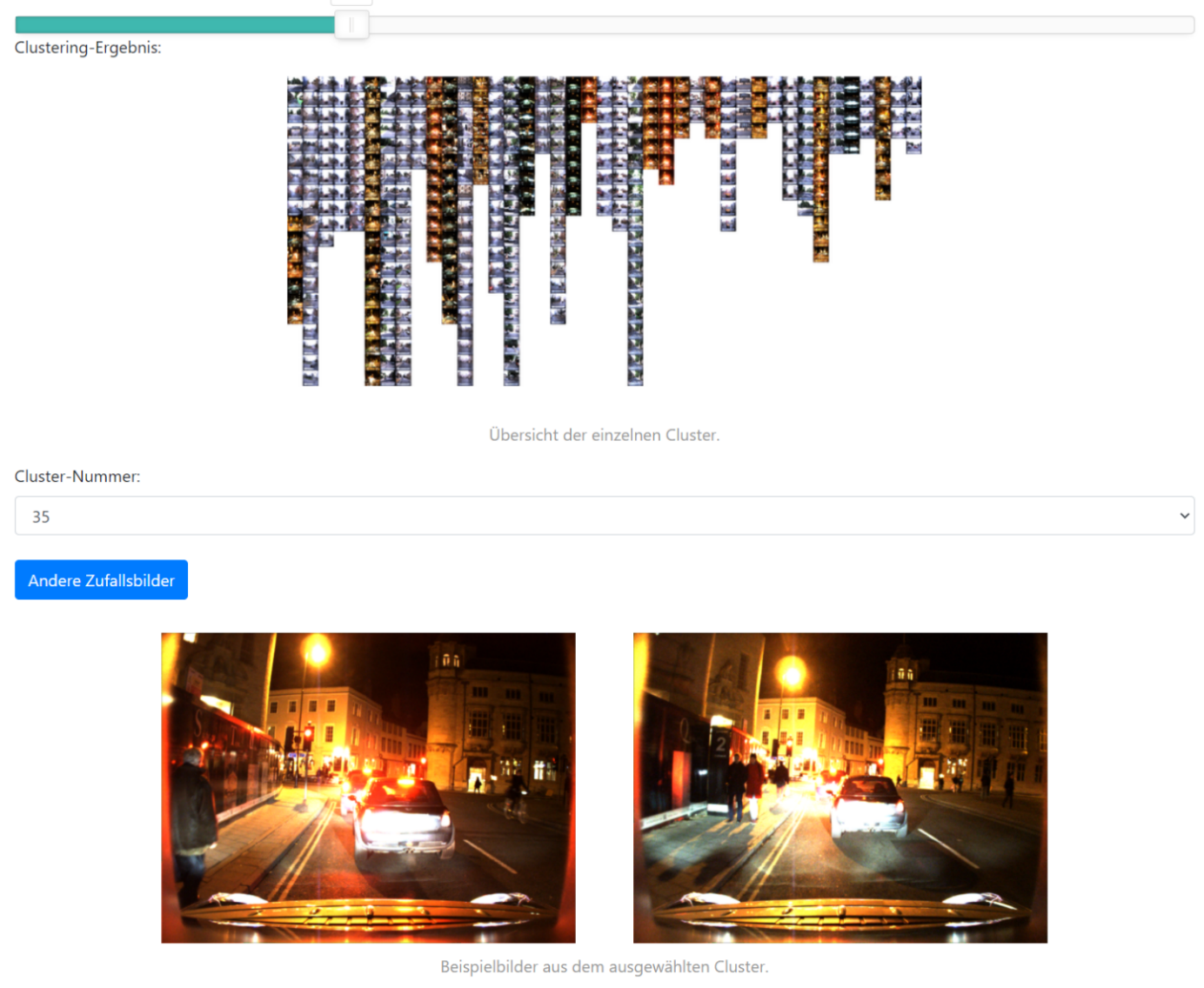
Die Analyse der Abdeckung eines Datensatzes ist je nach Anwendungsfall herausfordernd. Im Kontext der Funktionsentwicklung von Fahrerassistenzsystemen kann nicht immer exakt vorhergesagt werden, welche Fälle im produktiven Einsatz der Funktion auftreten können. Um trotzdem Informationen über die verschiedenen Inhalte des Datensatzes zu erhalten, können beispielsweise Clustering-Verfahren angewendet werden. Diese können dabei helfen, große Mengen ungelabelter Daten schnell zu analysieren und zu erfassen, ob gewisse Aspekte der Daten über- oder unterrepräsentiert sind (siehe Beispiel im Bild).
Wenn unterrepräsentierte Aspekte im Datensatz gefunden wurden, können diese Lücken durch Augmentierung, also die künstliche Generierung neuer, realistischer Daten, geschlossen werden. Dazu können Generative Adversarial Networks verwendet werden. Diese können so trainiert werden, dass bestehende Bilder nach der Aufnahme realistisch verändert werden (beispielsweise das Wetter) oder komplett neue Bilder entstehen.