ML-Komponentenentwicklung
Reiternavigation
Beschreibung
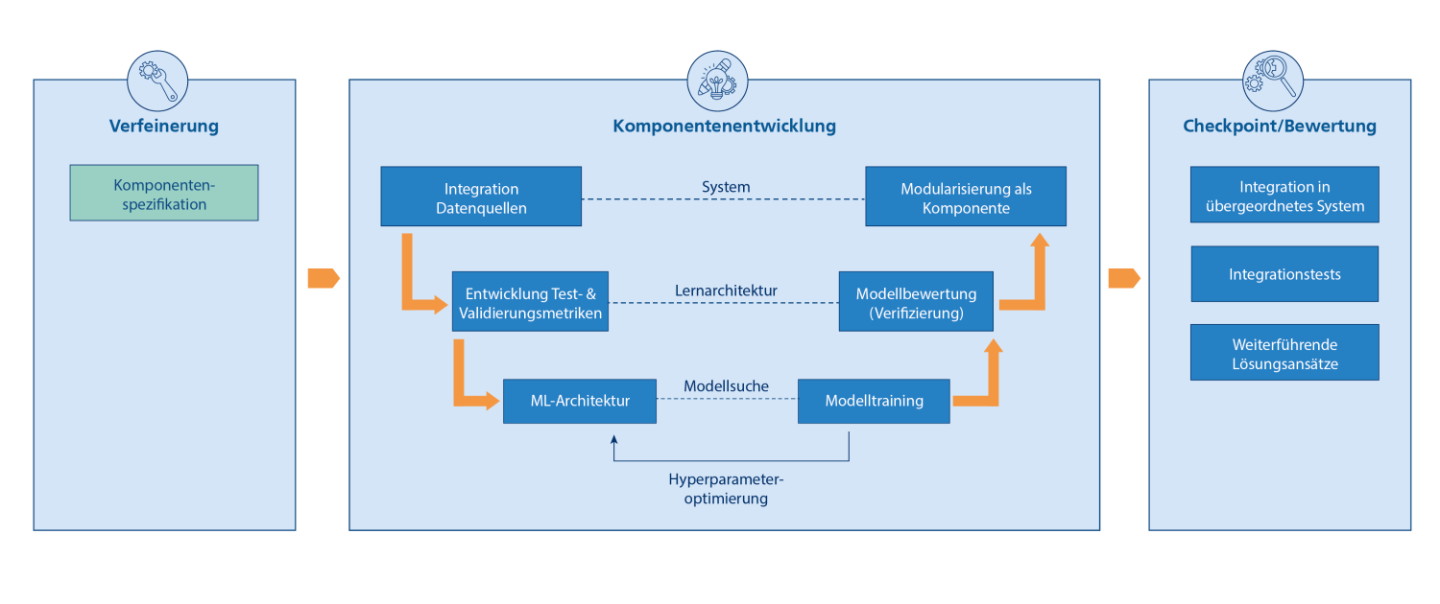
Das Vorgehen bei der ML-Komponentenentwicklung orientiert sich an dem im Software und Systems Engineering etablierten V-Modell. Ziel ist eine enge Integration mit ML-Hilfssystemen und Datenquellen, um innerhalb der Checkpoints Ergebnisse iterativ integrieren undvalidieren zu können.
Durch dieses Vorgehen soll ein ML-Modell (also der datengetrieben gelernte Teil) in eine möglichst genau spezifizierte Komponente gekapselt werden. Dabei wird eine organisatorische Schnittstelle zwischen der klassischen Data-Science-Disziplin und dem Systems Engineering geschaffen.
Ausgangspunkt ist die Spezifikation der Komponente im Kontext des umgebenden Systems, die innerhalb der Verfeinerung iterativ detailliert und angepasst wird. Zur Spezifikation zählt unter anderem das ML-Verfahren (z. B. Neuronales Netz, Entscheidungsbaum etc.) als möglicher Lösungsansatz auf Basis der Anforderungen an die Komponente. Bei dessen Wahl fließen sowohl übergeordnete Anforderungen an das Gesamtsystem ein (z. B. die Nachvollziehbarkeit von Entscheidungen) als auch direkte Abhängigkeiten von anderen Komponenten (z.B. beschränkte Rechenressourcen, Verfügbarkeit von Daten, Verfügbarkeit von Zielgrößen).
Der erste Schritt befasst sich mit der Integration der Datenquellen für Training, Tests und Validierung. Dabei kann es vorkommen, dass die Datenquellen und damit die Schnittstellen nicht in jedem Zyklus dieselben sind, z. B. falls zunächst Daten in Tabellenform vorliegen und später in einer Datenbank.
Bei der Entwicklung der Test- und Validierungsmetriken werden globale Kostenfunktionen aus den Anforderungen an die Komponente abgeleitet, die sich für die datengetriebene Bewertung eignen. Hierbei sollte Domänenwissen einfließen, um ML-Komponenten einzeln, jedoch mit Bezug auf ihre Funktion innerhalb des Gesamtsystems, testen zu können.
Das ML-Verfahren wird im nächsten Schritt zu einer konkreten ML-Architektur implementiert, mit festgelegten Hyperparametern. Beispiele hierfür sind die Festlegung der Anzahl der Neuronen und Schichten in künstlichen Neuronalen Netzen sowie die Definition der lokalen Kostenfunktion und Lernrate.
Die ML-Architektur wird im Modelltraining in ein für die zu erfüllende Funktionalität geeignetes ML-Modell überführt. Da die Ergebnisse des erlernten Modells stark von der ML-Architektur, also den gewählten Hyperparametern, abhängen, werden diese mehrfach variiert. Ziel ist es die Hyperparameterkonfigurationen zu finden, die auf Basis der lokalen Kostenfunktion und eines Validierungsdatensatzes zum besten Modell führen. Diese Hyperparameteroptimierung kann in vielen Fällen durch geeignete Werkzeuge teilweise oder komplett automatisiert werden (z.B. durch Auto-ML Systeme).
Bei der anschließenden Modellbewertung wird anhand eines Testdatensatzes und der zuvor definierten Test- und Validierungsmetriken die Güte des erlernten und optimierten ML-Modells bewertet. Somit lässt sich die Genauigkeit und Performanz des Modells bezüglich bisher ungesehener Daten und Metriken bewerten, die auf die zu erfüllende Funktionalität der Komponente zugeschnitten sind.
Der letzte Schritt innerhalb der ML-Komponentenentwicklung bildet die Modularisierung als Komponente. Hier wird das trainierte und validierte ML-Modell so aufbereitet, dass es auf die Zielplattform gebracht werden kann. Während das Modell zuvor nur auf Basis von Daten validiert wurde, wird nun sichergestellt, dass das Modell auf der Zielplattform, wie z.B. auf einem ressourcenbeschränkten eingebetteten System, lauffähig ist und dort vergleichbare Ergebnisse liefert.
Zum Checkpoint findet die eigentliche Integration der Komponenten in das übergeordnete System statt. Hier erst zeigt sich innerhalb von Tests, ob die Spezifikation und die Ableitung der Architektur gelungen ist und ob sich die komponentenspezifisch erreichten Metriken auch positiv auf das Gesamtsystem auswirken. Sollte dies nicht der Fall sein, sind weitere Zyklen notwendig, in denen in Absprache mit den anderen Komponenten weitere Lösungsansätze, wie z .B. andere ML-Verfahren, erprobt werden. Die Ziele weiterer Zyklen können ebenso über die Anforderungen hinausgehende Optimierungen sein, wie etwa die Steigerung der Vorhersagegenauigkeit des ML-Systems. Zur Steuerung des Entwicklungsprozesses ist es wichtig, dass innerhalb des Checkpoints anhand der erstellten Berichte Metriken in konkrete Schätzungen zu Kosten und Risiken übersetzt werden, um Entscheidungen bzgl. der Weiterentwicklung ableiten zu können.
Leitfragen
- Wie können Anforderungen in Test- und Validierungsmetriken überführt werden?
- Welche Kostenfunktionen eignen sich für das Modelltraining?
- Welches ML-Verfahren eignet sich, um eine optimale Komponente im Sinne des Gesamtsystems zu erhalten?
- Welche Verbesserungen können aufgrund von Veränderungen in anderen Subsystemen (z.B. Daten) erreicht werden?
- Gibt es verfügbare KI-Komponenten von externen Anbietern, die genutzt und weiterentwickelt werden können?
Ergebnisse
- ML-Komponente mit einer klaren Dokumentation der Anforderungen, der genutzten Daten und Werkzeuge
- Ergebnisse aus der Evaluierung von Test- und Validierungsmetriken
- Einschätzung zu Verbesserungspotenzialen in Abhängigkeit von anderen Subsystemen
- Kontinuierliches Test- und Überwachungskonzept der ML-Komponente unter Nutzung von Test- und Validierungsmetriken
← Zurück zum Entwicklungszyklus
Tablesort – Anwendungsfall Produktion
Hyperparameteroptimierung
Wurde eine Reihe von Versuchen durchgeführt und ein für die Anlage repräsentativer Datensatz erstellt, erfolgt im nächsten Zyklus die Entwicklung der ML-Komponente. Hierfür wird zunächst die Datenbank als Datenquelle in die Entwicklungsumgebung der ML-Komponente integriert.
Als Test- und Validierungsmetriken wird festgelegt, dass in einem Experiment von 10 Minuten Dauer eine Anomalie mit einer Dauer von einer Minute richtig erkannt werden soll. Im nächsten Schritt wird die Architektur des ML-Verfahrens festgelegt. Für den Tablesort Demonstrator werden unterschiedliche Neuronale Netze trainiert und auf ihre Zuverlässigkeit hinsichtlich richtiger Anomalieerkennung untersucht. . Dies entspricht dem Vorgang der Hyperparameteroptimierung in neben stehendem Prozessschaubild.
Ist die Entscheidung für eine ML-Architektur gefallen, wird das entsprechende ML-Modell anhand der Testdatensätze hinsichtlich der Zielmetriken verifiziert. Schlussendlich wird das ML-Modell in eine eigenständige Komponente mit entsprechenden Schnittstellen zu anderen Komponenten überführt. Die fertige Komponente wird zum Checkpoint mit anderen Komponenten integriert und getestet.
Für die ML-Komponentenentwicklung sind normalerweise mehrere Entwicklungszyklen nötig, in denen verschiedene Lösungsansätze ausprobiert werden, bis das Ergebnis zufriedenstellend ist.
Notbremssystem – Anwendungsfall Mobilität
Für diesen Einblick liegt der Fokus auf der Subsystementwicklung des Detektors. Dieser soll vorausfahrende Fahrzeuge im Videostream einer Einzelkamera erkennen. Beispielhaft wird hier die Entwicklung anhand eines schon vorhandenen externen Datensatzes namens „Cityscapes“ dargestellt.
Im Rahmen der Komponentenspezifikation wird folgender Lösungsansatz als vielversprechend bewertet: Die Aufgabe soll mithilfe eines künstlichen Neuronalen Netzwerks zur Erkennung von Objekten in Einzelbildern gelöst werden, das auf einer kleinen GPU-basierten Recheneinheit ausgeführt wird. Das Neuronale Netz erhält Kamerabilder über eine Ethernet-Schnittstelle, und gibt Ergebnisse über eine RAM-Schnittstelle an den Entscheider weiter, der ebenfalls auf dieser Recheneinheit ausgeführt wird. Zielvorgabe sind mindestens zwei Detektionen pro Fahrzeug innerhalb einer Sekunde Sichtbarkeit bei einem Abstand von bis zu 50 Metern Entfernung. Bei selteneren Detektionen darf der Tracker das Objekt als Fehldetektion verwerfen. Es sind weniger als 0,2 Prozent Fehler in dieser Detektion erlaubt.
Im Rahmen der Integration der Datenschnittstellen werden die technischen Schnittstellen im Zielsystem (Ethernet-Streams von Kamerabildern) in operative Schnittstellen (Videobilder im RAM) überführt, und die KI-bezogenen Softwareteile der Komponente aus der Embedded-Hardware gelöst, um sie beispielsweise auf einem PC oder in einem Rechencluster entwickeln, trainieren und testen zu können. Es wird festgelegt, dass das System zunächst in der Programmiersprache Python entwickelt wird, und aufgrund der fehlenden Datensätze aus dem Realsystem ein bestehender annotierter Fahrzeugdatensatz, Cityscapes22, verwendet wird, der dem Zielsystem grundsätzlich ähnelt.
Im Rahmen der Entwicklung von Test- und Validierungsmetriken werden die Anforderungen an die Komponente (zwei Detektionen pro Sekunde) auf Anforderungen an das spezifizierte ML-Verfahren adaptiert. Da dieses Verfahren nur eine Einzelbildauswertung nutzt, können Zeitdauern nicht direkt übernommen werden. Es wird eine Bildrate von 25 Bildern pro Sekunde angenommen und gefordert, dass unter 25 aufeinanderfolgenden Einzelbildern jedes Objekt mindestens zweimal erkannt worden sein muss. Außerdem darf diese Anforderung nur bei weniger als 0,2 Prozent der Objekte im Datensatz verletzt werden.
Im Rahmen der Wahl der ML-Architektur wird konkretisiert, dass ein „Mask R-CNN“-Ansatz23 gewählt wird, der Einzelobjekte anhand ihrer Bild-Pixelbereiche erkennt. Um dieses Neuronale Netz zu trainieren, muss die die Kostenfunktion auf Einzelbilder und ihre Pixel heruntergebrochen werden. Obwohl also eigentlich „erkannt“ vs. „nicht erkannt“ für ein ganzes Bild bewertet werden soll, ist eine dementsprechende Kostenfunktion für das Training ungeeignet. Praktischer ist es, im Training jeden falsch klassifizierten Pixel zu „bestrafen“ – und die Leistungsfähigkeit des Neuronalen Netzes über die gängige mIoU-Metrik zu bewerten. Hier findet ein wesentlicher Bruch in den Anforderungen statt: Es wird ein Netz trainiert, das Objektumrisse so genau wie möglich erkennt, um eine ML-Komponente zu erhalten, die Objekte möglichst häufig erkennt.
Das Modelltraining wird also auf Basis der mIoU-Metrik anhand des Cityscapes-Datensatzes durchgeführt. Sollten die Ergebnisse nicht zufriedenstellend sein, können Hyperparameter, wie z. B. die Anzahl der Schichten des Neuronalen Netztes, angepasst werden.
Im Rahmen der Modellbewertung wird das ML-Modell auf Grundlage der Einzelbildfolgen bewertet, das heißt, Objektumrisse aus dem Mask-R-CNN-Resultat werden auf hinreichende Größe geprüft und diese Metrik auf Bildsequenzen aus dem Cityscapes-Datensatz angewendet, um zu bewerten, ob das Ziel von zwei Detektionen je 25 Einzelbilder zumindest auf dem Cityscapes-Datensatz erfüllt wird.
Im Rahmen der Modularisierung als Komponente wird das System auf die GPU-Recheneinheit übertragen, und die CityscapesDatensatz-Bilder werden simulativ über die reale Ethernet-Schnittstelle eingespielt, um einen echten Videostream nachzubilden. Hier wird der Maßstab von zwei Detektionen je Sekunde auf der realen Plattform der Komponente erprobt, jedoch (in dieser Iteration) noch ohne reale Daten.
Die Komponente kann am Checkpoint jetzt in ihren Spezifikationen und mit der erreichten Ergebnisqualität auf Kompatibilität mit den parallel entwickelten Komponenten geprüft werden.
← Zurück zum Entwicklungszyklus