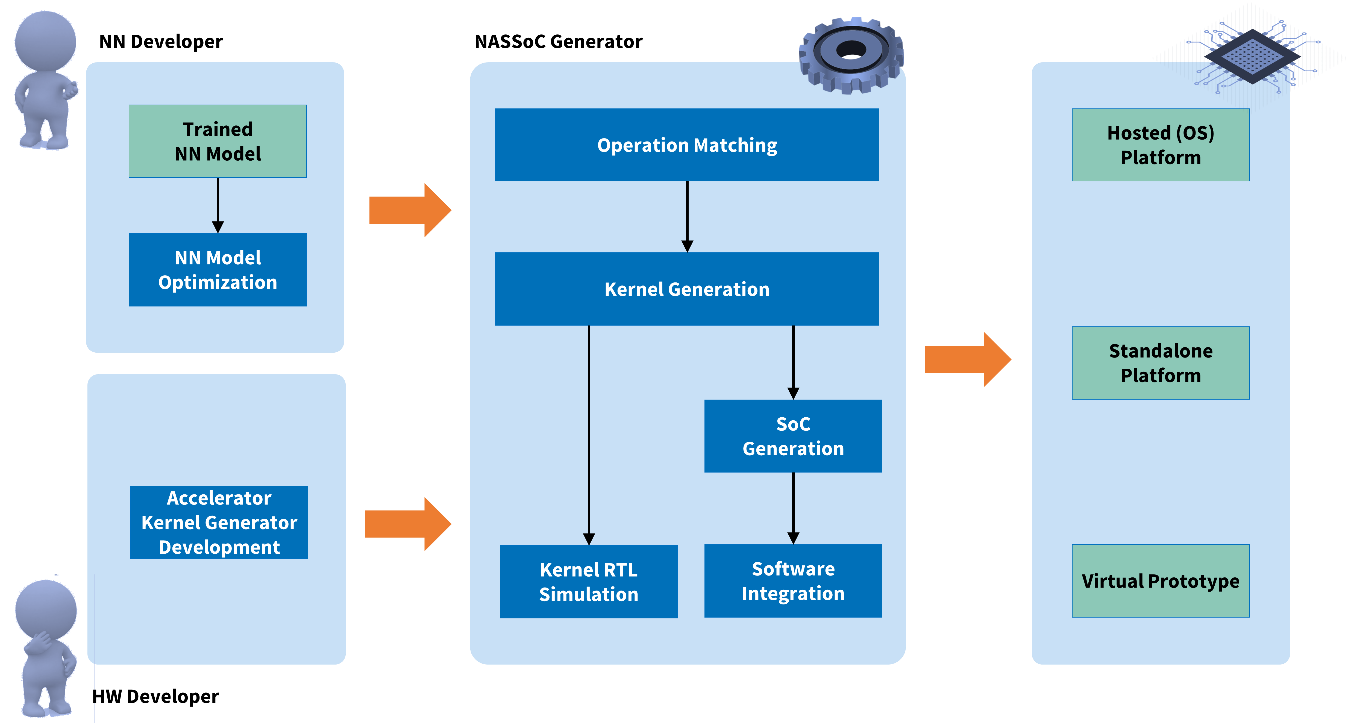
Der Neural Architecture Specific System-on-a-Chip (NASSoC) Generator erleichtert und automatisiert in vielen Bereichen die Entwicklung und Integration von HW-beschleunigten Architekturen in SoC-Plattformen für die Ausführung von künstlichen Neuronalen Netzen. Grundlage dafür war die Kombination von spezifischen Hardwaregeneratoren und TensorFlow Lite Modellen. Ein TensorFlow Lite Modell beschreibt eine Sequenz von komplexen parametrisierten Operatoren, welche das Neuronale Netz abbilden. Bei den Hardwaregeneratoren handelt es sich um Software, welche bei ihrer Ausführung als Ergebnis die Hardwarebeschreibung eines RISC-V-Prozessors inklusive angebundenem Hardware-Beschleuniger liefern. Diese Hardware-Beschleuniger können sowohl spezifisch an ein Modell angepasst sein als auch die Ausführung unterschiedlicher Modelle unterstützen. Hierdurch ist die flexible Abbildung neuronaler Netze auf die Ausführungsplattform möglich. Unterstützt werden Lösungen mit Betriebssystem sowie Bare-Metal-Implementierungen. Dabei können die Hardwarebeschleuniger komplett auf die Netzarchitektur adaptiert werden oder es wird durch generische Beschleuniger eine Menge von Netzarchitekturen unterstützt.
Zur Ausführung von TensorFlow Lite Modellen ist, zusätzlich zu der generierten Plattform, ein komplexer Anwendungsprozessor mit Linux Betriebssystem notwendig. Um den Overhead eines Betriebssystems zu umgehen, unterstützt das Framework zusätzlich TensorFlow Lite Micro bzw. µTVM basierte Lösungen, bei welchen die vollständige KI-Anwendung bare-metal auf dem eingebetteten RISC-V Prozessor samt Beschleuniger ausgeführt wird. Dabei kann, je nach Anwendungsfall, ein bestehender generalisierter Beschleuniger zum Einsatz kommen, oder ein spezifisch für das gegebene Modell generierter Beschleuniger. Im Fokus steht dabei die automatische Generierung der Softwareartefakte, welche zur Ausführung eines gegebenen Modells auf der beschleunigten Plattform notwendig sind.
Um das Deployment auf der Anwendungsplattform mit generalisiertem HW-Beschleuniger entsprechend der Parametrisierung zu ermöglichen, muss das NN-Modell maßgeblich angepasst werden. Ziel dieser Anpassung ist, dass das Modell analysiert und wenn nötig Operationen umgeformt werden, damit möglichst viele davon auf der beschleunigten Hardware ausgeführt werden können und nur wenige von der CPU übernommen werden müssen. Ein manuelles Abstimmen dieser Operationen kann sehr zeitaufwändig sein. Im Rahmen von CC-KING wurde das open-source Deployment-Framework TVM erweitert. Das Framework ermöglicht das Einlesen einer Vielzahl von NN-Modellformaten wie z.B. Tensorflow Lite. Mithilfe von TVM wird aus einem solchen Modell automatisiert Software spezifisch für die Ausführungsplattform generiert, die die nötige Ansteuerung des HW-Beschleunigers enthält. Mithilfe der µTVM-Runtime und einem Echtzeitbetriebssystem entsteht so eine abgeschlossene Firmware, die für die Inferenz verwendet wird.
Die generalisierte Beschleunigerarchitektur bietet ein hohes Maß an Flexibilität um verschiedene NN-Modelle auf einer generierten Hardwareplattform ausführen zu können. Wenn jedoch nur ein spezifisches Netz zum Einsatz kommen soll, kann ggf. eine effizientere Hardware erzeugt werden.
Dies geschieht mit Hilfe der eingangs erwähnten spezifischen Hardwaregeneratoren, welche für jede Operation des Netzes entsprechend parametrisierte Recheneinheiten erzeugt und zu einem Gesamtbeschleuniger verknüpft (siehe Abbildung). Um die Plattform von einem externen Anwendungsprozessor unabhängig zu machen, ist das Framework auch in der Lage die generierten Beschleuniger an TensorFlow Lite Micro anzubinden. Im Gegensatz zu TensorFlow Lite benötigt TensorFlow Lite Micro kein Betriebssystem, wodurch es vollständig in die Firmware des RISC-V Prozessors integriert werden kann. Das Framework erzeugt dabei sämtliche Routinen zur Ansteuerung des Beschleunigers und kapselt sie in eine entsprechende TensorFlow Lite Micro Operation.
Zur Ausführung von TensorFlow Lite Modellen ist, zusätzlich zu der generierten Plattform, ein komplexer Anwendungsprozessor mit Linux Betriebssystem notwendig. Um den Overhead eines Betriebssystems zu umgehen, unterstützt das Framework zusätzlich TensorFlow Lite Micro basierte Lösungen, bei welchen die vollständige KI-Anwendung auf dem eingebetteten RISC-V Prozessor samt Beschleuniger ausgeführt wird, ohne den Overhead des Betriebssystems. Im Fokus steht dabei die automatische Generierung der Softwareartefakte, welche zur Ausführung eines gegebenen Modells auf der beschleunigten Plattform notwendig sind. Dabei kann, je nach Anwendungsfall, ein bestehender generalisierter Beschleuniger zum Einsatz kommen, oder ein spezifisch für das gegebene Modell generierter Beschleuniger.
Um das Deployment auf der Anwendungsplattform mit generalisiertem HW-Beschleuniger entsprechend der Parametrisierung zu ermöglichen, muss das NN-Modell maßgeblich angepasst werden. Ziel dieser Anpassung ist, dass das Modell analysiert und wenn nötig Operationen umgeformt werden, damit möglichst viele davon auf der beschleunigten Hardware ausgeführt werden können und nur wenige von der CPU übernommen werden müssen. Ein manuelles Abstimmen dieser Operationen kann sehr zeitaufwändig sein. Im Rahmen von CC-KING wurde das open-source Deployment-Framework TVM erweitert. Das Framework ermöglicht das Einlesen einer Vielzahl von NN-Modellformaten wie z.B. Tensorflow Lite. Mithilfe von TVM wird aus einem solchen Modell automatisiert Software spezifisch für die Ausführungsplattform generiert, die die nötige Ansteuerung des HW-Beschleunigers enthält. Mithilfe der µTVM-Runtime und einem Echtzeitbetriebssystem entsteht so eine abgeschlossene Firmware, die für die Inferenz verwendet wird.
Die generalisierte Beschleunigerarchitektur bietet ein hohes Maß an Flexibilität um verschiedene NN-Modelle auf einer generierten Hardwareplattform ausführen zu können. Wenn jedoch nur ein spezifisches Netz zum Einsatz kommen soll, kann ggf. eine effizientere Hardware erzeugt werden.
Dies geschieht mit Hilfe der eingangs erwähnten spezifischen Hardwaregeneratoren, welche für jede Operation des Netzes entsprechend parametrisierte Recheneinheiten erzeugt und zu einem Gesamtbeschleuniger verknüpft (siehe Abbildung). Um die Plattform von einem externen Anwendungsprozessor unabhängig zu machen, ist das Framework auch in der Lage die generierten Beschleuniger an TensorFlow Lite Micro anzubinden. Im Gegensatz zu TensorFlow Lite benötigt TensorFlow Lite Micro kein Betriebssystem, wodurch es vollständig in die Firmware des RISC-V Prozessors integriert werden kann. Das Framework erzeugt dabei sämtliche Routinen zur Ansteuerung des Beschleunigers und kapselt sie in eine entsprechende TensorFlow Lite Micro Operation.